
Abstract
A common requirement in practice is to periodically rotate the keys used to encrypt stored data. Systems used by Amazon and Google do so using a hybrid encryption technique which is eminently practical but has questionable security in the face of key compromises and does not provide full key rotation. Meanwhile, symmetric updatable encryption schemes (introduced by Boneh et al. CRYPTO 2013) support full key rotation without performing decryption: ciphertexts created under one key can be rotated to ciphertexts created under a different key with the help of a re-encryption token. By design, the tokens do not leak information about keys or plaintexts and so can be given to storage providers without compromising security. But the prior work of Boneh et al. addresses relatively weak confidentiality goals and does not consider integrity at all. Moreover, as we show, a subtle issue with their concrete scheme obviates a security proof even for confidentiality against passive attacks.
This paper presents a systematic study of updatable Authenticated Encryption (AE). We provide a set of security notions that strengthen those in prior work. These notions enable us to tease out real-world security requirements of different strengths and build schemes that satisfy them efficiently. We show that the hybrid approach currently used in industry achieves relatively weak forms of confidentiality and integrity, but can be modified at low cost to meet our stronger confidentiality and integrity goals. This leads to a practical scheme that has negligible overhead beyond conventional AE. We then introduce re-encryption indistinguishability, a security notion that formally captures the idea of fully refreshing keys upon rotation. We show how to repair the scheme of Boneh et al., attaining our stronger confidentiality notion. We also show how to extend the scheme to provide integrity, and we prove that it meets our re-encryption indistinguishability notion. Finally, we discuss how to instantiate our scheme efficiently using off-the-shelf cryptographic components (AE, hashing, elliptic curves). We report on the performance of a prototype implementation, showing that fully secure key rotations can be performed at a throughput of approximately 116 kB/s.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



1 Introduction
To cryptographically protect data while stored, systems use authenticated encryption (AE) schemes that provide strong message confidentiality as well as ciphertext integrity. The latter allows detection of active attackers who manipulate ciphertexts. When data is stored for long periods of time, good key management practice dictates that systems must support key rotation: moving encrypted data from an old key to a fresh one. Indeed, key rotation is mandated by regulation in some contexts, such as the payment card industry data security standard (PCI DSS) that dictates how credit card data must be secured [PCI16]. Key rotation can also be used to revoke old keys that are comprised, or to effect data access revocation.
Deployed approaches to key rotation. Systems used in practice typically support a type of key rotation using a symmetric key hierarchy. Amazon’s Key Management Service [AWS], for example, enables users to encrypt a plaintext M under a fresh data encapsulation key via \(C_{dem} = \textsf {Enc} (K_d,M)\) and then wrap \(K_d\) via \(C_{kem} = \textsf {Enc} (K,K_d)\) under a long-term key K owned by the client. Here \(\textsf {Enc} \) is an authenticated encryption (AE) scheme. By analogy with the use of hybrid encryption in the asymmetric setting, we refer to such a scheme as a KEM/DEM construction, with KEM and DEM standing for key and data encapsulation mechanisms, respectively; we refer to the specific scheme as AE-hybrid.
The AE-hybrid scheme then allows a simple form of key rotation: the client picks a fresh \(K'\) and re-encrypts \(K_d\) as \(C'_{kem} = \textsf {Enc} (K',\textsf {Dec} (K,C_{kem}))\). Note that the DEM key \(K_d\) does not change during key rotation. When deployed in a remote storage system, a client can perform key rotation just by fetching from the server the small, constant-sized ciphertext \(C_{kem}\), operating locally on it to produce \(C'_{kem}\), and then sending \(C'_{kem}\) back to the server. Performance is independent of the actual message length. The Google Cloud Platform [Goo] uses a similar approach to enable key rotation.
To our knowledge, the level of security provided by this widely deployed AE-hybrid scheme has never been investigated, let alone formally defined in a security model motivated by real-world security considerations. It is even arguable whether AE-hybrid truly rotates keys, since the DEM key does not change. Certainly it is unclear what security is provided if key compromises occur, one of the main motivations for using such an approach in the first place. On the other hand, the scheme is fast and requires only limited data transfer between the client and the data store, and appears to be sufficient to meet current regulatory requirements.
Updatable encryption. Boneh, Lewi, Montgomery, and Raghunathan (BLMR) [BLMR15] (the full version of [BLMR13]) introduced another approach to enabling key rotation that they call updatable encryption. An updatable encryption scheme is a symmetric encryption scheme that, in addition to the usual triple of \((\textsf {KeyGen},\textsf {Enc},\textsf {Dec})\) algorithms, comes with a pair of algorithms \(\textsf {ReKeyGen} \) and \(\textsf {ReEnc} \). The first, \(\textsf {ReKeyGen} \), generates a compact rekey token given the old and new secret keys and a target ciphertext, while the second, \(\textsf {ReEnc} \), uses a rekey token output by the first to rotate the ciphertext without performing decryption. For example, AE-hybrid can be seen as an instance of an updatable encryption scheme in which the rekey token output by \(\textsf {ReKeyGen} \) is \(C'_{kem}\) and where \(\textsf {ReEnc} \) simply replaces \(C_{kem}\) with \(C'_{kem}\). BLMR introduced an IND-CPA-style security notion in which adversaries can additionally obtain some rekey tokens. Their definition is inspired by, but different from, those used for CCA-secure proxy re-encryption schemes [CH07]. Given its obvious limitations when it comes to key rotation, it is perhaps surprising that the AE-hybrid construction provably meets the BLMR confidentiality notion for updatable encryption schemes.
BLMR also introduced and targeted a second security notion for updatable encryption, called ciphertext independence. It demands that a ciphertext and its rotation to another key are identically distributed to a ciphertext and a rotation of another ciphertext (for the same message). The intuition is that this captures the idea that true key rotation should refresh all randomness used during encryption. This definition is not met by the AE-hybrid construction above. But it is both unclear what attacks meeting their definition would prevent, and, relatedly, whether more intuitive definitions exist.
BLMR gave a construction for an updatable encryption scheme and claimed that it provably meets their two security definitions. Their construction cleverly combines an IND-CPA KEM with a DEM that uses a key-homomorphic PRF [NPR99, BLMR15] to realize a stream cipher. This enables rotation of both the KEM and the DEM keys, though the latter requires a number of operations that is linear in the plaintext length. Looking ahead, their proof sketch has a bug and we provide strong evidence that it is unlikely to be fixable. Moreover, BLMR do not yet target or achieve any kind of authenticated encryption goal, a must for practical use.
Our contributions. We provide a systematic treatment of AE schemes that support key rotation without decryption, a.k.a. updatable AE.
Specifically, we provide a new security notion for confidentiality, \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \), that is strictly stronger than that of BLMR [BLMR15], a corresponding notion for integrity, \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) (missing entirely from BLMR but essential for practice), and a new notion called re-encryption indistinguishability (\(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \)) that is strictly stronger and more natural in capturing the spirit of “true key rotation” than the ciphertext indistinguishability notion of BLMR.
Achieving our \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) notion means that an attacker, having access to both a ciphertext and the secret key used to generate it, should not be able to derive any information that helps it attack a rotation of that ciphertext. Thus, for example, an insider with access to the encryption keys at some point in time but who is then excluded from the system cannot make use of the old keys to learn anything useful once key rotation has been carried out on the AE ciphertexts. Teasing out the correct form of this notion turns out to be a significant challenge in our work.
Armed with this set of security notions, we go on to make better sense of the landscape of constructions for updatable AE schemes. Table 1 summarises the security properties of the different schemes that we consider. Referring to this table, our security notions highlight the limitations of the AE-hybrid scheme: while it meets the confidentiality notion of BLMR, it only satisfies our \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) notions when considering a severely weakened adversary who has no access to any compromised keys. We propose an improved construction, KSS, that satisfies both notions for any number of compromised keys and which is easily deployable via small adjustments to AE-hybrid. KSS uses a form of secret sharing to embed key shares in the KEM and DEM components to avoid the issue of leaking the DEM key in the updating process, and adds a cryptographic hash binding the KEM and DEM components to prevent mauling attacks. These changes could easily be adopted by practitioners with virtually no impact on performance, while concretely improving security.
However, the improved scheme KSS cannot satisfy our \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) notion, because it still uses a KEM/DEM-style approach in which the DEM key is never rotated. The BLMR scheme might provide \( \mathrm{{UP}}\text {-}\mathrm{{REENC}} \) security, but, as noted above, its security proof contains a bug which we consider unlikely to be fixable. Indeed, we show that proving the BLMR scheme confidential would imply that one could also prove circular security [BRS03, CL01] for a particular type of hybrid encryption scheme assuming only the key encapsulation is IND-CPA secure. Existing counter-examples of IND-CPA secure, but circular insecure, schemes [ABBC10, CGH12] do not quite rule out such a result. But the link to the very strong notion of circular security casts doubt on the security of this scheme. One can easily modify the BLMR scheme to avoid this issue, but even having done so the resulting encryption scheme is still trivially malleable and so cannot meet our \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) integrity notion.
We therefore provide another new scheme, \({\mathrm{{ReCrypt}}}\), meeting all three of our security notions: \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \), \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \). We take inspiration from the previous constructions, especially that of BLMR: key-homomorphic PRFs provide the ability to fully rotate encryption keys; the KEM/DEM approach with secret sharing avoids the issue of leaking the DEM key in the updating process; and finally, adding a cryptographic hash to the KEM tightly binds the KEM and DEM portions and prevents ciphertext manipulation. We go on to instantiate the scheme using the Random Oracle Model (ROM) key-homomorphic PRF from [NPR99], having the form \(H(M)^{k}\), where H is a hash function into a group in which DDH is hard. This yields a construction of an updatable AE scheme meeting all three of our security notions in the ROM under the DDH assumption. We report on the performance of an implementation of \({\mathrm{{ReCrypt}}}\) using elliptic curve groups, concluding that it is performant enough for practical use with short plaintexts. However, because of its reliance on exponentiation, \({\mathrm{{ReCrypt}}}\) is still orders of magnitude slower than our KSS scheme (achieving only \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) security). This, currently, is the price that must be paid for true key rotation in updatable encryption.
Summary. In summary, the main contributions of this paper are:
-
To provide the first definitions of security for AE supporting key rotation without exposing plaintext.
-
To explain the gap between existing, deployed schemes using the KEM/DEM approach and “full” refreshing of ciphertexts.
-
To provide the first proofs of security for AE schemes using the KEM/DEM approach, namely AE-hybrid and KSS.
-
To detail the first updatable AE scheme, \({\mathrm{{ReCrypt}}}\), that fully and securely refreshes ciphertexts by way of key rotations without ever exposing plaintext data. We implement a prototype and report on microbenchmarks, showing that rotations can be performed in less than 9 µs per byte.
2 Updatable AE
We turn to formalizing the syntax and semantics of AE schemes supporting key rotation. Our approach extends that of Boneh et al. [BLMR15] (BLMR), the main syntactical difference being that we allow rekey token generation, re-encryption, and decryption to all return a distinguished error symbol \(\bot \). This is required to enable us to later cater for integrity notions. We also modify the syntax so that ciphertexts include two portions, a header and a body. In our formulation, only the former is used during generation of rekey tokens (while in BLMR the full ciphertext is formally required).
Definition 1 (Updatable AE)
An updatable AE scheme is a tuple of algorithms  with the following properties:
with the following properties:
-
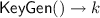 . Outputs a secret key \(k_{}\).
. Outputs a secret key \(k_{}\). -
 . On input a secret key \(k_{}\) and message m, outputs a ciphertext \(C = (\tilde{C},\overline{C})\) consisting of a ciphertext header \(\tilde{C}\) and ciphertext body \(\overline{C}\).
. On input a secret key \(k_{}\) and message m, outputs a ciphertext \(C = (\tilde{C},\overline{C})\) consisting of a ciphertext header \(\tilde{C}\) and ciphertext body \(\overline{C}\). -
 . On input two secret keys, \(k_{1}\) and \(k_{2}\), and a ciphertext header \(\tilde{C}\), outputs a rekey token or \(\bot \).
. On input two secret keys, \(k_{1}\) and \(k_{2}\), and a ciphertext header \(\tilde{C}\), outputs a rekey token or \(\bot \). -
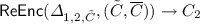 . On input a rekey token and ciphertext, outputs a new ciphertext or \(\bot \). We require that \(\textsf {ReEnc} \) is deterministic.
. On input a rekey token and ciphertext, outputs a new ciphertext or \(\bot \). We require that \(\textsf {ReEnc} \) is deterministic. -
 . On input a secret key \(k_{}\) and ciphertext C outputs either a message or \(\bot \).
. On input a secret key \(k_{}\) and ciphertext C outputs either a message or \(\bot \).
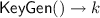 . Outputs a secret key
. Outputs a secret key  . On input a secret key
. On input a secret key  . On input two secret keys,
. On input two secret keys, 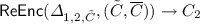 . On input a rekey token and ciphertext, outputs a new ciphertext or
. On input a rekey token and ciphertext, outputs a new ciphertext or  . On input a secret key
. On input a secret key Of course we require that all algorithms are efficiently computable. Note that, in common with [BLMR15], our definition is not in the nonce-based setting that is widely used for AE. Rather, we will assume that \(\textsf {Enc} \) is randomised. We consider this sufficient for a first treatment of updatable AE; it also reflects common industry practice as per the schemes currently used by Amazon [AWS] and Google [Goo]. We relegate the important problem of developing a parallel formulation in the nonce-based setting to future work. Similarly, we assume that all our AE schemes have single decryption errors, cf. [BDPS14], and we do not consider issues such as release of unverified plaintext, cf. [ABL+14], tidiness, cf. [NRS14] and length-hiding, cf. [PRS11].

Interaction between client and cloud during a ciphertext-dependent update. Client retrieves a small ciphertext header, and runs \(\textsf {ReKeyGen} \) to produce a compact rekey token \(\varDelta \). The cloud uses this token to re-encrypt the data. At the end of the update, the data is encrypted using \(k_{2}\), and cannot be recovered using only \(k_{1}\).
Correctness. An updatable AE scheme is correct if decrypting a legitimately generated ciphertext reproduces the original message. Of course, legitimate ciphertexts may be rotated through many keys, complicating the formalization of this notion.
Definition 2 (Correctness)
Fix an updatable AE scheme \(\varPi \). For any message m and any sequence of secret keys \(k_{1}, \dots k_{T}\) output by running  T times, let
T times, let  and recursively define for \(1 \le t < T\)
and recursively define for \(1 \le t < T\)

Then \(\varPi \) is correct if  with probability 1.
with probability 1.
Compactness. We say that an updatable AE scheme is compact if the size of both ciphertext headers and rekeying tokens are independent of the length of the plaintext. In practice the sizes should be as small as possible, and for the constructions we consider these are typically a small constant multiple of the key length.
Compactness is important for efficiency of key rotation. Considering the abstract architecture in Fig. 1, header values must be available to the key server when rekey tokens are generated. Typically this will mean having to fetch them from storage. Likewise, the rekey token must be sent back to the storage system. Note that there are simple constructions that are not compact, such as the one that sets \(\tilde{C}\) to be a standard authenticated encryption of the message and in which \(\textsf {ReKeyGen} \) decrypts \(\tilde{C}\), re-encrypts it, and outputs a “rekeying token” as the new ciphertext.
Ciphertext-dependence. As formulated above, updatable AE schemes require part of the ciphertext, the ciphertext header \(\tilde{C}\), in order to generate a rekey token. We will also consider schemes for which \(\tilde{C}\) is the empty string, denoted \(\varepsilon \). We will restrict attention to schemes for which encryption either always outputs \(\tilde{C}= \varepsilon \) or never does. In the former case we call the scheme ciphertext-independent and, in the latter case, ciphertext-dependent. When discussing ciphertext-independent schemes, we will drop \(\tilde{C}\) from notation, e.g., writing  instead of
instead of  .
.
However, we primarily focus on ciphertext-dependent schemes which appear to offer more flexibility and achieve stronger security guarantees (though it is an open question whether a ciphertext-independent scheme can achieve our strongest security notion). We do propose a very lightweight ciphertext-independent scheme included in Appendix A.1, but we show it achieves strictly weaker confidentiality and integrity notions. One can generically convert a ciphertext-independent scheme into a ciphertext-dependent one, simply by deriving a ciphertext-specific key using some unique identifier for the ciphertext. We omit the formal treatment of this trivial approach.
Directionality of rotations. Some updatable AE schemes are bidirectional, meaning rekey tokens can be used to go forwards or backwards.
We only consider bi-directionality to be a feature of ciphertext-independent schemes. Formally, we say that a scheme is bidirectional if there exists an efficient algorithm \(\textsf {Invert} (\cdot )\) that produces a valid rekey token  when given
when given  as input.
as input.
Schemes that are not bidirectional might be able to ensure that an adversary cannot use rekey tokens to “undo” a rotation of a ciphertext. We will see that ciphertext-dependence can help in building such unidirectional schemes, whereas ciphertext-independent schemes seem harder to make unidirectional. This latter difficulty is related to the long-standing problem of constructing unidirectional proxy re-encryption schemes in the public key setting.
Relationship to proxy re-encryption. Proxy re-encryption targets a different setting than updatable encryption (or AE): the functional ability to allow a ciphertext encrypted under one key to be converted to a ciphertext decryptable by another key. The conversion should not leak plaintext data, but, unlike key rotation, it is not necessarily a goal of proxy re-encryption to remove all dependency on the original key, formalised as indistinguishability of re-encryptions (UP-REENC security) in our work. For example, previous work [CK05, ID03] suggests twice encrypting plaintexts under different keys. To rotate, the previous outer key and a freshly generated outer key is sent to the proxy to perform conversion, but the inner key is never modified. Such an approach does not satisfy the goals of key rotation.
That said, any bidirectional, ciphertext-independent updatable AE ends up also being usable as a symmetric proxy re-encryption scheme (at least as formalized by [BLMR15]).
3 Confidentiality and Integrity for Updatable Encryption
Updatable AE should provide confidentiality for messages as well as integrity of ciphertexts, even in the face of adversaries that obtain rekey tokens and re-encryptions, and that can corrupt some number of secret keys. Finding definitions that rule out trivial wins—e.g., rotating a challenge ciphertext to a compromised key, or obtaining sequences of rekey tokens that allow such rotations — is delicate. We provide a framework for doing so.
Our starting point will be a confidentiality notion which improves significantly upon the previous notion of BLMR by including additional attack vectors, and strengthening existing ones.
For ciphertext integrity, we develop a new definition, building on the usual INT-CTXT notion for standard AE [BN00]. Looking ahead, we will target unidirectional schemes that simultaneously achieve both \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) security.
We will follow a concrete security approach in which we do not strictly define security, but rather measure advantage as a function of the resources (running time and number of queries) made by an adversary. Informally, schemes are secure if no adversary with reasonable resources can achieve advantage far from zero.
3.1 Message Confidentiality
The confidentiality game \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) is shown in the leftmost column of Fig. 2. The adversary’s goal is to guess the bit b. Success implies that a scheme leaks partial information about plaintexts. We paramaterise the game by two values t and \(\kappa \). The game initialises \(t + \kappa \) secret keys, \(\kappa \) of which are given to the adversary, and t are kept secret for use in the oracles. We label the keys by \(k_{1}, \dots , k_{t}\) for the uncompromised keys, and by \(k_{t+1}, \dots k_{t+\kappa }\) for the compromised keys. We require at least one uncompromised key, but do not necessarily require any compromised keys, i.e. \(t \ge 1\) and \(\kappa \ge 0\). We leave consideration of equivalences between models with many keys and few keys and between models with active and static key compromises as interesting problems for future work.

Confidentiality and integrity games for updatable encryption security.
The game relies on two subroutines \(\textsf {Invalid}_{\textsf {RK}}\) and \(\textsf {Invalid}_{\textsf {RE}}\) to determine if a re-keygen and re-encryption query, respectively, should be allowed. These procedures are efficiently computed by the game as a function of the adversarial queries and responses. This reliance on the transcript we leave implicit in the notation to avoid clutter. Different choices of invalidity procedures gives rise to distinct definitions of security, and we explain two interesting ones in turn. Note that an invalid query (as determined by \(\textsf {Invalid}_{\textsf {RE}}\)) still results in the adversary learning the ciphertext header, giving greater power to the adversary. We believe this to be an important improvement both in practice and theoretically over previous models, which consider only a partial compromise. The full compromise of a client results in the adversary playing the role of the client in the key update procedure, during which the server will return the ciphertext header. In practice, it is likely that an adversary who has initially breached the client would use this access to query related services.
Invalidity procedures. For the invalidity constraints used in \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \), we target a strong definition, while preventing the adversary from trivially receiving a challenge ciphertext re-encrypted to a compromised key.
We use the ciphertext headers to determine whether a ciphertext has been derived from a challenge ciphertext. It is natural to use only the headers since these will be processed by the client when performing an update. We define a procedure \(\textsf {Derived}_{\textsf {LR}} (i,\tilde{C})\) that outputs \(\mathsf{true}\) should \(\tilde{C}\) have been derived from the ciphertext header returned by an \(\text {LR} \) query.
Definition 3 (LR-derived headers)
We recursively define function  to output \(\mathsf{true}\) iff any of the following conditions hold:
to output \(\mathsf{true}\) iff any of the following conditions hold:
-
\(\tilde{C}\) was the ciphertext header output in response to a query \(\text {LR} (i,m_0,m_1)\)
-
\(\tilde{C}\) was the ciphertext header output in response to a query \(\text {ReEnc} (j,i,C')\) and
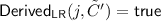
-
\(\tilde{C}\) is the ciphertext header output by running
 where
where  is the result of a query \(\text {ReKeyGen} (j,i,\tilde{C}')\) for which
is the result of a query \(\text {ReKeyGen} (j,i,\tilde{C}')\) for which  .
.
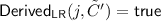
 where
where  is the result of a query
is the result of a query  .
.The predicate \(\textsf {Derived}_{\textsf {LR}} (i,\tilde{C})\) is efficient to compute and can be computed locally by the adversary. The most efficient way to implement it is to grow a look-up table \(\mathtt {T}\) indexed by a key identifier and a ciphertext header and whose entries are sets of ciphertexts. Any query to \(\text {LR} (i,m_0,m_1)\) updates the table by adding the returned ciphertext to the set \(\mathtt {T}[i,\tilde{C}]\) where \(\tilde{C}\) is the oracle’s returned ciphertext header value. For a query \(\text {ReEnc} (j,i,C')\), if \(\mathtt {T}[j,\tilde{C}']\) is not empty, then it adds the returned ciphertext to the set \(\mathtt {T}[i,\tilde{C}^*]\) for \(\tilde{C}^*\) the returned ciphertext header. For a query \(\text {ReKeyGen} (j,i,\tilde{C}')\) with return value  , apply
, apply  for all ciphertexts C found in entry \(\mathtt {T}[j,\tilde{C}']\) and add appropriate new entries to the table. In this way, one can maintain the table in worst-case time that is quadratic in the number of queries, and compute in constant time \(\textsf {Derived}_{\textsf {LR}} (i,\tilde{C})\) by simply checking if \(\mathtt {T}[i,\tilde{C}]\) is non-empty. If any call to \(\textsf {ReKeyGen}\) or \(\textsf {ReEnc}\) in \(\textsf {Derived}_{\textsf {LR}}\) or the main oracle procedure returns \(\bot \), then the entire procedure returns \(\bot \).
for all ciphertexts C found in entry \(\mathtt {T}[j,\tilde{C}']\) and add appropriate new entries to the table. In this way, one can maintain the table in worst-case time that is quadratic in the number of queries, and compute in constant time \(\textsf {Derived}_{\textsf {LR}} (i,\tilde{C})\) by simply checking if \(\mathtt {T}[i,\tilde{C}]\) is non-empty. If any call to \(\textsf {ReKeyGen}\) or \(\textsf {ReEnc}\) in \(\textsf {Derived}_{\textsf {LR}}\) or the main oracle procedure returns \(\bot \), then the entire procedure returns \(\bot \).
Note that \(\textsf {Derived}_{\textsf {LR}} \) relies on \(\textsf {ReEnc} \) being deterministic, a restriction we made in Sect. 2. To complete the definition, we specify the invalidity procedures that use \(\textsf {Derived}_{\textsf {LR}} \) as a subroutine:
-
\(\textsf {Invalid}_{\textsf {RK}}(i,j,\tilde{C})\) outputs \(\mathsf{true}\) if \(j > t\) and \(\textsf {Derived}_{\textsf {LR}} (i,\tilde{C}) = \mathsf{true}\). In words, the target key is compromised and \(i,\tilde{C}\) derives from an \(\text {LR} \) query.
-
\(\textsf {Invalid}_{\textsf {RE}}(i,j,\tilde{C})\) outputs \(\mathsf{true}\) if \(j > t\) and \(\textsf {Derived}_{\textsf {LR}} (i,\tilde{C}) = \mathsf{true}\). In words, the target key is compromised and \(i,\tilde{C}\) derives from an \(\text {LR} \) query.
We denote the game defined by using these invalidity procedures by \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \). We associate to an \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) adversary \({\mathcal {A}}\) and scheme \(\varPi \) the advantage measure:

This notion is very strong and bidirectional schemes cannot meet it.
Theorem 1
Let \(\varPi \) be a bidirectional updatable encryption scheme. Then there exists an \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) adversary \({\mathcal {A}}\) that makes 2 queries and for which

for any \(\kappa \ge 1\) and \(t \ge 1\).
Proof
We explicitly define the adversary \({\mathcal {A}}\). It makes a query to \(C_1 = \text {LR} (1,m_0,m_1)\) for arbitrary messages \(m_0 \ne m_1\) and computes locally \(C_{t+1} = \textsf {Enc} (k_{t+1},m_1)\). It then makes a query  . It runs
. It runs  locally and then decrypts \(C'\) using \(k_{t+1}\). It checks whether the result is \(m_0\) or \(m_1\) and returns the appropriate bit. \(\square \)
locally and then decrypts \(C'\) using \(k_{t+1}\). It checks whether the result is \(m_0\) or \(m_1\) and returns the appropriate bit. \(\square \)
BLMR confidentiality. In comparison, we define invalidity procedures corresponding to those in BLMR’s security notion.
-
\(\textsf {InvalidBLMR}_{\textsf {RK}}(i,j,\tilde{C})\) outputs \(\mathsf{true}\) if \(i \le t < j\) or \(j \le t < i\) and outputs \(\mathsf{false}\) otherwise. In words, the query is not allowed if exactly one of the two keys is compromised.
-
\(\textsf {InvalidBLMR}_{\textsf {RE}}(i,j,\tilde{C})\) outputs \(\mathsf{true}\) if \(j > t\) and \(\mathsf{false}\) otherwise. In words, the query is not allowed if the target key \(k_{j}\) is compromised.
We denote the game defined by using these invalidity procedures by \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) (the naming will become clear presently). We associate to an \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) adversary \({\mathcal {A}}\), scheme \(\varPi \), and parameters \(\kappa ,t\) the advantage measure:

A few observations are in order. First, it is apparent that the invalidity procedures for the BLMR notion are significantly stronger than ours, leading to a weaker security notion: the BLMR procedures are not ciphertext-specific but instead depend only on the compromise status of keys. We will show that this difference is significant. In addition, the corresponding BLMR definition did not consider leakage of the ciphertext header when \(\textsf {InvalidBLMR}_{\textsf {RE}}\) returns \(\mathsf{true}\). Second, for ciphertext-independent schemes in which \(\tilde{C}= \varepsilon \) always, the BLMR definition coincides with symmetric proxy re-encryption security (as also introduced in their paper [BLMR15]). Third, the BLMR confidentiality notion does not require unidirectional security of rekey tokens because it has the strong restriction of disallowing attackers from obtaining rekey tokens  with \(i > t\) (so the corresponding key is compromised), but with \(j < t\) (for an uncompromised key). Thus, in principle, bidirectional schemes could meet this notion, explaining our naming convention for the notion. Finally, the BLMR notion does not require ciphertext-specific rekey tokens because the invalidity conditions are based only on keys and not on the target ciphertext.
with \(i > t\) (so the corresponding key is compromised), but with \(j < t\) (for an uncompromised key). Thus, in principle, bidirectional schemes could meet this notion, explaining our naming convention for the notion. Finally, the BLMR notion does not require ciphertext-specific rekey tokens because the invalidity conditions are based only on keys and not on the target ciphertext.
Detailed in Appendix A.1 is a bidirectional scheme that is secure in the sense of \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \). This result and the negative result that no bidirectional scheme can achieve \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) given above (Theorem 1) yields as a corollary that \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) security is strictly weaker than \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) security. This illustrates the enhanced strength of our \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) security notion compared to the corresponding BLMR notion, \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \).
Given that bidirectional, ciphertext-independent schemes have certain advantages in terms of performance and deployment simplicity, practitioners may prefer them in some cases. For that flexibility, one trades off control over the specificity of rekey tokens, which could be dangerous to confidentiality in some compromise scenarios.
3.2 Ciphertext Integrity
We now turn to a notion of integrity captured by the game \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) shown in Fig. 2. The adversary’s goal is to submit a ciphertext to the \(\text {Try}\) oracle that decrypts properly. Of course, we must exclude the adversary from simply resubmitting valid ciphertexts produced by the encryption oracle, or derived from such an encryption by way of re-encryption queries or rekey tokens.
In a bit more detail, in the \(\text {Try}\) oracle, we define a predicate \(\textsf {InvalidCTXT}_{\textsf {}}\) which captures whether the adversary has produced a trivial derivation of a ciphertext obtained from the encryption oracle. This fulfills a similar role to that of the \(\textsf {Invalid}_{\textsf {RE}}\) and \(\textsf {Invalid}_{\textsf {RK}}\) subroutines in the UP-IND game.
For the unidirectional security game \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \), we define \(\textsf {InvalidCTXT}_{\textsf {}}(i, C = (\tilde{C},\overline{C}))\) inductively, outputting \(\mathsf{true}\) if any of the following conditions hold:
-
\(i > t\), i.e. \(k_{i}\) is known to the adversary
-
\((\tilde{C}, \overline{C})\) was output in response to a query \(\text {Enc} (i, m)\)
-
\((\tilde{C}, \overline{C})\) was output in response to a query \(\text {ReEnc} (j,i,C')\) and \(\textsf {InvalidCTXT}_{\textsf {}}(j,C') = \mathsf{true}\)
-
\((\tilde{C}, \overline{C})\) is the ciphertext output by running
 for \(C' = (\tilde{C}', \overline{C}')\) where
for \(C' = (\tilde{C}', \overline{C}')\) where  was the result of a query \(\text {ReKeyGen} (j,i,\tilde{C}')\) and \(\textsf {InvalidCTXT}_{\textsf {}}(j,C')) = \mathsf{true}\).
was the result of a query \(\text {ReKeyGen} (j,i,\tilde{C}')\) and \(\textsf {InvalidCTXT}_{\textsf {}}(j,C')) = \mathsf{true}\).
 for
for  was the result of a query
was the result of a query This predicate requires the transcript of queries thus far; to avoid clutter we leave the required transcript implicit in our notation. The definition of \(\textsf {InvalidCTXT}_{\textsf {}}\) is quite permissive: it defines invalid ciphertexts as narrowly as possible, making our security notion stronger. Notably, the adversary can produce any ciphertext (valid or otherwise) using a corrupted key \(k_{i}\), and use the ReKeyGen oracle to learn a token to update this ciphertext to a non-compromised key. Only the direct re-encryption of the submitted ciphertext is forbidden.
We associate to an updatable encryption scheme \(\varPi \), an \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) adversary \({\mathcal {A}}\), and parameters \(\kappa ,t\) the advantage measure:

4 Practical Updatable AE Schemes
We first investigate the security of updatable AE schemes built using the KEM/DEM approach sketched in the introduction. Such schemes are in widespread use at present, for example in AWS’s and Google’s cloud storage systems, yet have received no formal analysis to date. We produce the AE-hybrid construction as a formalism of this common practice.
Using the confidentiality and integrity definitions from the previous section, we discover that this construction offers very weak security against an adversary capable of compromising keys. Indeed, we are only able to prove security when the number of compromised keys \(\kappa \) is equal to 0. Given the intention of key rotation this is a somewhat troubling result.
On a positive note, we show a couple of simple tweaks to the AE-hybrid which fix these issues. The resultant scheme, named KSS, offers improved security at little additional cost.
We leave to the appendix our bidirectional, ciphertext-independent scheme XOR-KEM which does not offer strong integrity guarantees but may be of interest for other applications.
4.1 Authenticated Encryption
In the following constructions we make use of authenticated encryption (AE) schemes which we define here.
Definition 4 (Authenticated encryption)
An authenticated encryption scheme \(\pi \) is a tuple of algorithms \((\mathcal {K}, \mathcal {E}, \mathcal {D})\). \(\mathcal {K}\) is a randomised algorithm outputting keys. We denote by \(\mathcal {E}_k(\cdot )\) the randomised algorithm for encryption by key k, and by \(\mathcal {D}_k(\cdot )\) decryption. Decryption is a deterministic algorithm and outputs the distinguished symbol \(\perp \) to denote a failed decryption.
In keeping with our definitional choices for updatable AE, we consider randomised AE schemes rather than nonce-based ones.
We use the all-in-one authenticated encryption security definition from [RS06].
Definition 5 (Authenticated Encryption Security)
Let \(\pi = ({\mathcal {K}}, {\mathcal {E}}, {\mathcal {D}})\) be an authenticated encryption scheme. Let \(\text {Enc}\), \(\text {Dec}\) be oracles whose behaviors depends on hidden values \(b \in \{0,1\}\) and key  . \(\text {Enc}\) takes as input a bit string m and produces \(\mathcal {E}_k(m)\) when \(b=0\), and produces a random string of the same length otherwise. \(\text {Dec}\) takes as input a bit string C and produces \(\mathcal {D}_k(C)\) when \(b=0\), and produces \(\bot \) otherwise.
. \(\text {Enc}\) takes as input a bit string m and produces \(\mathcal {E}_k(m)\) when \(b=0\), and produces a random string of the same length otherwise. \(\text {Dec}\) takes as input a bit string C and produces \(\mathcal {D}_k(C)\) when \(b=0\), and produces \(\bot \) otherwise.
Let \(\mathrm{{AE}}\text {-}\mathrm{{ROR}} ^{{\mathcal {A}}}_{\pi }\) be the game in which an adversary \({\mathcal {A}}\) interacts with the \(\text {Enc} \) and \(\text {Dec} \) oracles and must output a bit \(b'\). The game outputs \(\mathsf{true}\) when \(b = b'\). We require that the adversary not submit outputs from the \(\text {Enc} \) oracle to the \(\text {Dec} \) oracle.
We define the advantage of \({\mathcal {A}}\) in the AE-ROR security game for \(\pi \) as:

Unless otherwise stated, our AE schemes will be length-regular, so that the lengths of ciphertexts depend only on the lengths of plaintexts. This ensures that the above definition also implies a standard “left-or-right” security definition.
4.2 (In-)Security of AE-Hybrid Construction
Figure 3 defines an updatable AE scheme, AE-hybrid, for any AE scheme \(\pi = ({\mathcal {K}}, {\mathcal {E}}, {\mathcal {D}})\). This is a natural key-wrapping scheme that one might create in the absence of security definitions. It is preferred by practitioners because key rotation is straightforward and performant. Using this scheme means re-keying requires constant time and communication, independent of the length of the plaintext. In fact, we note that this scheme sees widening deployment for encrypted cloud storage services. Both Amazon Web Services [AWS] and Google Cloud Platform [Goo] use AE-hybrid to perform key rotations over encrypted customer data.
We demonstrate severe limits of AE-hybrid: when keys are compromised confidentiality and integrity cannot be recovered through re-encryption. Later we will demonstrate straightforward modifications to AE-hybrid that allow it to recover both confidentiality and integrity without impacting performance.

Algorithms for the AE-hybrid updatable AE scheme.
Theorem 2
(AE-hybrid insecurity in the \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) sense). Let \(\pi = ({\mathcal {K}}, {\mathcal {E}}, {\mathcal {D}})\) be a symmetric encryption scheme and \(\varPi \) be the updatable AE scheme AE-hybrid built using \(\pi \) as defined in Fig. 3.
Then there exists an adversary \({\mathcal {A}}\) making 2 queries such that  for all \(\kappa \ge 1\) and \(t \ge 1\).
for all \(\kappa \ge 1\) and \(t \ge 1\).
Proof
We construct a concrete adversary \({\mathcal {A}}\) satisfying the theorem statement.
\({\mathcal {A}}\) makes an initial query to \(\text {LR} (1, m_0, m_1)\) for distinct messages \(m_0 \ne m_1\) and receives challenge ciphertext \(C^* = (\mathcal {E}(k_{1}, x), \mathcal {E}(x, m_b))\). \({\mathcal {A}}\) subsequently calls \(\text {ReKeyGen} (1, t+1, C^*)\). \(k_{t+1}\) is corrupted and thus \(\textsf {Invalid}_{\textsf {RK}}\) returns \(\mathsf{true}\), so the adversary receives the re-encrypted ciphertext header \(\tilde{C}' = \mathcal {E}(k_{t+1}, x)\).
The adversary decrypts \(x = \mathcal {D}(k_{t_1}, \tilde{C}')\), computes \(m_b = \mathcal {D}(x, \overline{C}^*)\) and checks whether \(m_b = m_0\) or \(m_1\). \(\square \)
The best one can achieve with this scheme is to prove security when \(\kappa = 0\), that is, security is not degraded beyond the underlying AE scheme when the adversary does not obtain any compromised keys. However, such a weak security notion is not particularly interesting, since the intention of key rotation is to provide enhanced security in the face of key compromises. We give proofs for the weak security of the AE-hybrid scheme in the full version.
Similarly, AE-hybrid is trivially insecure in the UP-INT sense when \(\kappa \ge 1\).
Theorem 3
(AE-hybrid insecurity in the \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) sense). Let \(\pi = ({\mathcal {K}}, {\mathcal {E}}, {\mathcal {D}})\) be a symmetric encryption scheme and \(\varPi \) be the updatable AE scheme AE-hybrid built using \(\pi \) as defined in Fig. 3.
Then there exists an adversary \({\mathcal {A}}\) making 2 queries and one \(\text {Try} \) query such that  for all \(\kappa \ge 1\) and \(t \ge 1\).
for all \(\kappa \ge 1\) and \(t \ge 1\).
Proof
We construct a concrete adversary \({\mathcal {A}}\) satisfying the theorem statement.
\({\mathcal {A}}\) first queries \(\text {Enc} (1, m)\) to obtain an encryption \(C = (\mathcal {E}(k_{1}, x), \mathcal {E}(x, m))\), and subsequently queries \(\text {ReEnc} (1, t+1, C)\), receiving the re-encryption \(C' = (\mathcal {E}(k_{t+1}, x), \mathcal {E}(x, m))\). Since \({\mathcal {A}}\) has key \(k_{t+1}\), \({\mathcal {A}}\) recovers \(x = \mathcal {D}(k_{t+1},\tilde{C}')\) by performing the decryption locally.
Finally, \({\mathcal {A}}\) constructs the ciphertext \(C^* = (\tilde{C}, \mathcal {E}(x, m'))\) for some \(m' \ne m\) and queries \(\text {Try} (1, C^*)\). Since \(C^*\) is not derived from C and \(k_{1}\) is not compromised, \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) outputs \(\mathsf{true}\). \(\square \)
4.3 Improving AE-Hybrid
We make small modifications to the AE-hybrid construction and show that the resulting construction has both \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) security. These modifications include masking the DEM key stored inside the ciphertext header (to gain \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) security), and including an encrypted hash of the message (for \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \)). We note that these modifications are straightforward to implement on top of the AE-hybrid scheme and have only minimal impact on the scheme’s performance in practice.
Let (\(\mathcal {K}\), \(\mathcal {E}\), \(\mathcal {D}\)) be an AE scheme and h a hash function with \(\ell _h\) output bits. Then we define KSS (KEM/DEM with Secret Sharing) as in Fig. 4.

Algorithms for the KSS updatable AE scheme.
Theorem 4
(UP-IND Security of KSS). Let \(\pi = ({\mathcal {K}}, {\mathcal {E}}, {\mathcal {D}})\) be a symmetric encryption scheme and \(\varPi \) be the updatable AE scheme KSS built using \(\pi \) as defined in Fig. 4. Then for any adversary \({\mathcal {A}}\) for the game UP-IND, making at most q queries to the \(\text {LR} \) oracle, there exists an adversary \(\mathcal {B}\) for the AE security game where:

for all \(\kappa \ge 0, t \ge 1\).
For brevity, we leave the full proof to the full version, but we briefly outline the proof here. The proof proceeds in two phases. In the first phase, we use a series of t game-hops to replace ciphertext headers produced by \(\textsf {Enc} \) under each of t keys with random strings of the same length. We bound the difference between each game with an AE adversary. In the second phase, we use q game-hops (one for each \(\text {LR} \) query): each hop replacing encryption of the DEM with a call to an AE encryption oracle. Again, we bound the difference between each game with an AE adversary and in the end we get the stated result.
Our modification to include an encrypted hash of the ciphertext is in order to provide a measure of integrity protection. As we will see in the following theorem, collision resistance of the hash function is sufficient to provide UP-INT security, since the hash itself is integrity-protected by the AE encryption of the KEM. The hash itself is encrypted in order to avoid compromise of the ciphertext header being sufficient to distinguish messages.
We achieve collision resistance by assuming h to be a random oracle. However, this assumption could be avoided by either re-using the DEM key x to additionally key the hash function.
We note that this combination of hash function and AE encryption is used to provide an additional integrity mechanism that works for any AE scheme. However, some schemes may be able to avoid this additional computation by re-using components of the AE encryption. For example, if an encrypt-then-MAC scheme is used such that the encryption and MAC keys are both uniquely derived from the DEM key x, then we conjecture that the MAC itself can be used in place of the encrypted hash.
Theorem 5
(UP-INT Security of KSS). Let \(\pi = ({\mathcal {K}}, {\mathcal {E}}, {\mathcal {D}})\) be a symmetric encryption scheme, h be a cryptographic hash function modelled as a random oracle with output length \(\ell _h\), and \(\varPi \) be the updatable AE scheme KSS built using \(\pi \) and h as defined in Fig. 4. Then for any polynomial-time adversary \({\mathcal {A}}\), making at most \(q_h\) queries to the random oracle h, there exists an adversary \(\mathcal {B}\) for the AE security game where:

for all \(\kappa \ge 0, t \ge 1\).
This proof follows a similar format to the previous one: after t game hops to establish the integrity of the ciphertext headers using t AE adversaries, the adversary’s success depends on finding two ciphertexts which produce a collision in h. We leave the full proof to the full version.
5 Indistinguishability of Re-encryptions
The KSS scheme in the previous section achieves message confidentiality and ciphertext integrity, even though the actual DEM key is not modified in the course of performing a rotation. Modifying the scheme to ensure the DEM key is also rotated is non-trivial, requiring either significant communication complexity (linear in the length of the encrypted message) between the key server and storage, or the introduction of more advanced primitives such as key- homomorphic PRFs. The question that arises is whether or not changing DEM keys leaves KSS vulnerable to attacks not captured by the definitions introduced thus far.
BLMR’s brief treatment of updatable encryption attempts to speak to this issue by requiring that all randomness be refreshed during a rotation. Intuitively this would seem to improve security, but the goal they formalize for this, detailed below, is effectively a correctness condition (i.e., it does not seem to account for adversarial behaviors). It doesn’t help clarify what attacks would be ruled out by changing DEM keys.
Exfiltration attacks. We identify an issue with our KSS scheme (and the other schemes in the preceding section) in the form of an attack that is not captured by the confidentiality definitions introduced so far. Consider our simple KSS scheme in the context of our motivating key server and storage service application (described in Sect. 2). Suppose an attacker compromises for some limited time both the key server and the storage service. Then for each ciphertext \((\tilde{C},\overline{C})\) encrypted under a key \(k_{1}\), the attacker can compute the DEM key \(y \oplus \chi = x\) and exfiltrate it.
Suppose the compromise is cleaned up, and the service immediately generates new keys and rotates all ciphertexts to new secret keys. For the KSS scheme, the resulting ciphertexts will still be later decryptable using the previously exfiltrated DEM keys.
Although a confidentiality issue—the attacker later obtains access to plaintext data they should not have—our UP-IND security notion (and, by implication, the weaker BLMR confidentiality notion) do not capture these attacks. Technically this is because the security game does not allow a challenge ciphertext to be encrypted to a compromised key (or rotated to one). Intuitively, the UP-IND notion gives up on protecting the plaintexts underlying such ciphertexts, as the attacker in the above scenario already had access to the plaintext in the first phase of the attack.
One might therefore argue that this attack is not very important. All of the plaintext data eventually at risk of later decryption was already exposed to the adversary in the first time period because she had access to both the key and ciphertexts. But quantitatively there is a difference: for a given ciphertext an adversary in the first time period can exfiltrate just |x| bits per ciphertext to later recover as much plaintext as she likes, whereas the trivial attack may require exfiltrating the entire plaintext.
The chosen-message attack game of \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) does not capture different time periods in which the adversary knows plaintexts in the first time period but “forgets them” in the next. One could explicitly model this, perhaps via a two-stage game with distinct adversaries in each stage, but such games are complex and often difficult to reason about (cf., [RSS11]). We instead develop what we believe is a more intuitive route that asks that the re-encryption of a ciphertext should leak nothing about the ciphertext that was re-encrypted. We use an indistinguishability-style definition to model this. The interpretation of our definition is that any information derivable from a ciphertext (and its secret key) before a re-encryption isn’t helpful in attacking the re-encrypted version.
Re-encryption indistinguishability. We formalize this idea via the game shown in Fig. 5. The adversary is provided with a left-or-right re-encryption oracle, \(\text {ReLR}\), instead of the usual left-or-right encryption oracle, in addition to the usual collection of compromised keys, a re-encryption oracle, encryption oracle, and rekey token generation oracle. We assume that the adversary always submits ciphertext pairs such that \(|C_0| = |C_1|\).

The game used to define re-encryption indistinguishability.
To avoid trivial wins, the game must disallow the adversary from simply re-encrypting the challenge to a corrupted key. Hence we define a \(\textsf {Derived}_{\textsf {ReLR}} \) predicate, which is identical to the \(\textsf {Derived}_{\textsf {LR}} \) predicated defined in Sect. 3 for \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) security, except that it uses the \(\text {ReLR} \) challenge oracle. We give it in full detail in the next definition.
Definition 6 (ReLR-derived headers)
We recursively define the function  to output \(\mathsf{true}\) iff \(\tilde{C}\ne \varepsilon \) and any of the following conditions hold:
to output \(\mathsf{true}\) iff \(\tilde{C}\ne \varepsilon \) and any of the following conditions hold:
-
\(\tilde{C}\) was the ciphertext header output in response to a query \(\text {ReLR} (i,C_0,C_1)\).
-
\(\tilde{C}\) was the ciphertext header output in response to a query \(\text {ReEnc} (j,i,C')\) and
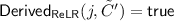 .
. -
\(\tilde{C}\) is the ciphertext header output by running
 where
where  is the result of a query \(\text {ReKeyGen} (j,i,C')\) for which
is the result of a query \(\text {ReKeyGen} (j,i,C')\) for which 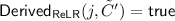 .
.
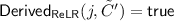 .
. where
where  is the result of a query
is the result of a query 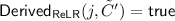 .
.Then the subroutines \(\textsf {Invalid}_{\textsf {RK}}, \textsf {Invalid}_{\textsf {RE}}\) used in the game output true if \(\textsf {Derived}_{\textsf {ReLR}} (i, \tilde{C})\) outputs true and \(j > t\). We associate to an updatable encryption scheme \(\varPi \), \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) adversary \({\mathcal {A}}\), and parameters \(\kappa ,t\) the advantage measure:

Informally, an updatable encryption scheme is \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) secure if no adversary can achieve advantage far from zero given reasonable resources (run time, queries, and number of target keys).
Notice that exfiltration attacks as discussed informally above would not apply to a scheme that meets \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) security. Suppose otherwise, that the exfiltration still worked. Then one could build an \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) adversary that worked as follows. It obtains two encryptions of different messages under a compromised key, calculates the DEM key (or whatever other information is useful for later decryption) and then submits the ciphertexts to the \(\text {ReLR} \) oracle, choosing as target a non-compromised key (\(j\le t\)). Upon retrieving the ciphertext, it uses the DEM key to decrypt, and checks which message was encrypted. Of course our notion covers many other kinds of attacks, ruling out even re-encryption that allows a single bit of information to leak.
BLMR re-encryption security. BLMR introduced a security goal that we will call basic re-encryption indistinguishability.Footnote 1 In words, it asks that the distribution of a ciphertext and its re-encryption should be identical to the distribution of a ciphertext and a re-encryption of a distinct ciphertext of the same message. More formally we have the following experiment, parameterized by a bit b and message m.

Then BLMR require that for all m and all ciphertext pairs \((C,C')\)

where the probabilities are over the coins used in the experiments.
This goal misses a number of subtleties which are captured by our definition. Our definition permits the adversary, for example, to submit any pair of ciphertexts to the \(\text {ReLR}\) oracle. This includes ciphertexts which are encryptions of distinct messages, and even maliciously formed ciphertexts which may not even decrypt correctly. It is simple to exhibit a scheme that meets the BLMR notion but trivially is insecure under ours.Footnote 2
On the other hand, suppose a distinguisher exists that can with some probability \(\epsilon \) distinguish between the outputs of \(\mathrm{{UP}}\text {-}\mathrm{{REENC0}} _{1,m}\) and \(\mathrm{{UP}}\text {-}\mathrm{{REENC0}} _{0,m}\) for some m. Then there exists an adversary against our \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) notion which achieves advantage \(\epsilon \). This can be seen by the following simple argument. The adversary gets  and submits the tuple \((1, 2, C, C')\) to its \(\text {ReLR}\) oracle and receives a re-encryption of one of the ciphertexts, \(C^*\). The adversary then runs the distinguisher on \((C,C^*)\) and outputs whatever the distinguisher guesses. If the distinguisher is computationally efficient, then so too is the \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) adversary.
and submits the tuple \((1, 2, C, C')\) to its \(\text {ReLR}\) oracle and receives a re-encryption of one of the ciphertexts, \(C^*\). The adversary then runs the distinguisher on \((C,C^*)\) and outputs whatever the distinguisher guesses. If the distinguisher is computationally efficient, then so too is the \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) adversary.
6 Revisiting the BLMR Scheme
The fact that the simple KEM/DEM schemes of Sect. 4 fail to meet re-encryption security begs the question of finding new schemes that achieve it, as well as \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) security. Our starting point is the BLMR construction of an updatable encryption from key-homomorphic PRFs. Their scheme does not (nor did it attempt to) provide integrity guarantees, and so trivially does not meet \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \). But before seeing how to adapt it to become suitable as an updatable AE scheme, including whether it meets our stronger notions of \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) security, we first revisit the claims of \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) security from [BLMR15].
As mentioned in the introduction, BLMR claim that the scheme can be shown secure, and sketch a proof of \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) security. Unfortunately the proof sketch contains a bug, as we explain below. Interestingly revelation of this bug does not lead to a direct attack on the scheme, and at the same time we could not determine if the proof could be easily repaired. Instead we are able to show that a proof is unlikely to exist.
Our main result of this section is the following: giving a proof showing the BLMR \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) security would imply the existence of a reduction showing that (standard) IND-CPA security implies circular security [BRS03, CL01] for a simple KEM/DEM style symmetric encryption scheme. The latter seems quite unlikely given the known negative results about circular security [ABBC10, CGH12], suggesting that the BLMR scheme is not likely to be provably secure.
First we recall some basic tools that BLMR use to build their scheme.
Definition 7
(Key-homomorphic PRF [BLMR15]). Consider an efficiently computable function \(F : \mathcal {K}\times \mathcal {X}\rightarrow \mathcal {Y}\) such that \((\mathcal {K}, \oplus )\) and \((\mathcal {Y}, \otimes )\) are both groups. We say that the tuple \((F, \oplus , \otimes )\) is a key-homomorphic PRF if the following properties hold:
-
1.
F is a secure pseudorandom function.
-
2.
For every \(k_1, k_2 \in \mathcal {K}\) and every \(x \in \mathcal {X}\), \(F(k_1 , x) \otimes F(k_2 , x) = F(k_1 \oplus k_2 , x)\).
A simple example in the ROM is the function \(F(k, x) = H(x)^k\) where \(\mathcal {Y}= \mathbb {G}\) is a group in which the decisional Diffie–Hellman assumption holds.
As an application of key-homomorphic PRFs, BLMR proposed the following construction. The construction follows a similar approach to the AE-hybrid scheme, but by using a key-homomorphic PRF in place of regular encryption the data encryption key can also be rotated.
Definition 8 (BLMR scheme)
Let \(\pi \) be a symmetric-key IND-CPA encryption scheme \(\pi = (\mathcal {KG}, \mathcal {E}, \mathcal {D})\). Furthermore, let \(F : \mathcal {K}\times \mathcal {X}\rightarrow \mathcal {Y}\) be a key-homomorphic PRF where \((\mathcal {K}, +)\) and \((\mathcal {Y}, +)\) are groups.
The BLMR scheme is the tuple of algorithms ( ,
,  ,
,  ,
,  ,
,  ) defined as follows:
) defined as follows:
-
\(\textsf {KeyGen} ()\): returns \(k \leftarrow \mathcal {KG}()\).
-
\(\textsf {Enc} (k_{}, m)\): samples a random
 and returns \(\tilde{C}= \mathcal {E}(k, x)\), and \(\overline{C}= (m_1 + F(x, 1), \ldots , m_{\ell } + F(x, \ell ))\).
and returns \(\tilde{C}= \mathcal {E}(k, x)\), and \(\overline{C}= (m_1 + F(x, 1), \ldots , m_{\ell } + F(x, \ell ))\). -
\(\textsf {ReKeyGen} (k_{1}, k_{2}, \tilde{C})\): computes \(x = \mathcal {D}(k_{1}, \tilde{C})\), samples a random
 and returns
and returns 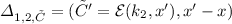 .
. -
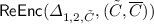 : parses token as
: parses token as  , computes \(\overline{C}' = (\overline{C}_1 + F(y, 1), \ldots \overline{C}_{\ell } + F(y, l))\) and returns \((\tilde{C}' \overline{C}')\).
, computes \(\overline{C}' = (\overline{C}_1 + F(y, 1), \ldots \overline{C}_{\ell } + F(y, l))\) and returns \((\tilde{C}' \overline{C}')\). -
\(\textsf {Dec} (k_{}, (\tilde{C}, \overline{C}))\): computes \(x = \mathcal {D}(\tilde{C})\) and returns \(m = (\overline{C}_1 - F(x, 1), \ldots \overline{C}_{\ell } - F(x, l))\).
 and returns
and returns  and returns
and returns 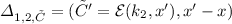 .
.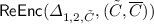 : parses token as
: parses token as  , computes
, computes Note that encryption here essentially performs a key wrapping step followed by CTR mode encryption using the wrapped key x and PRF F.
6.1 Negative Result About Provable UP-IND Security of BLMR
BLMR sketch a proof for the security of this construction in the \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) model (as we refer to it). However, the proof misses a subtle point: the interaction with the \(\textsf {ReKeyGen}\) oracle behaves similarly to a decryption oracle and the informal argument given that the IND-CPA security of the KEM is sufficient to argue security is wrong. In fact, the ReCrypt scheme seems unlikely to be provably secure even in our basic security model. To argue this, we show that proving security of the BLMR scheme implies the 1-circular security of a specific KEM/DEM construction. Figure 6 depicts the security game capturing a simple form of 1-circular security for an encryption scheme \(\pi = (\mathcal {KG}, \mathcal {E}, \mathcal {D})\).
While our main result here (Theorem 6), can be stated for the BLMR scheme as described earlier, for the sake of simplicity we instead give the result for the special case of using a simple one-time pad DEM instead of the key-homomorphic PRF. This is a trivial example of what BLMR call a key-homomorphic PRG, and their theorem statement covers this construction as well. We will show that proving security for this special case is already problematic, and this therefore suffices to call into question their (more general) theorem. Thus encryption becomes \(\textsf {Enc} (k_{},m) = \mathcal {E}(k,r),r\oplus m\) where \(\mathcal {E}\) is an IND-CPA secure KEM. We assume \(|m| = n\). We then have \(\textsf {ReKeyGen} (k_{1}, k_{2}, \tilde{C}) = (\mathcal {E}(k_{2}, r'), r' \oplus \mathcal {D}(k_{1}, \tilde{C}))\). We have the following theorem:

Left: The 1-circular security game. Right: Definition of \(\overline{\mathcal {E}}, \overline{\mathcal {D}} \) used in the proof of Theorem 6.

Adversary \(\mathcal {B}\) for UP-IND using as a subroutine the adversary \({\mathcal {A}}\) attacking 1-circular security of \(\textsf {EncBad} \).
Theorem 6
If one can reduce the ReCrypt \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \)-security to the IND-CPA security of \(\mathcal {E}\), then one can show a reduction that \(\textsf {Enc} \) is 1-circular secure assuming \(\mathcal {E}\) is IND-CPA.
Proof
We start by introducing a slight variant of \(\mathcal {E}\), denoted \(\overline{\mathcal {E}}\), shown in Fig. 6. It adds a bit to the ciphertextFootnote 3 that is read during decryption: if the bit is 1 then decryption outputs the secret key xor’d with the plaintext. Let \(\textsf {EncBad} \) be the same as \(\textsf {Enc} \) above but using \(\overline{\mathcal {E}} \), i.e., \(\textsf {EncBad} (k_{},m) = \overline{\mathcal {E}} (k,r),r\oplus m\) and \(\textsf {ReKeyGenBad} (k_{1},k_{2},C) = \overline{\mathcal {E}} (k_{2},r'),r'\oplus \overline{\mathcal {D}} (k_{1},C)\).
If \(\mathcal {E}\) is IND-CPA then \(\overline{\mathcal {E}} \) is as well. Thus if \(\overline{\mathcal {E}} \) is IND-CPA, then the security claim of BLMR implies that \(\textsf {EncBad} \) is \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \). We will now show that \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) security of \(\textsf {EncBad} \) implies the 1-circular security of \(\textsf {EncBad} \). In turn it’s easy to see that if \(\textsf {EncBad} \) is 1-circular secure then so too is \(\textsf {Enc} \), and, putting it all together, the claim of BLMR implies a proof that IND-CPA of \(\mathcal {E}\) gives 1-circular security of \(\textsf {Enc} \).
It remains to show that \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) security implies \(\textsf {EncBad} \) 1-circular security. Let \({\mathcal {A}}\) be a 1-circular adversary against \(\textsf {EncBad} \). Then we build an adversary \({\mathcal {B}}\) against the \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) security of \(\textsf {EncBad} \). It is shown in Fig. 7. The adversary makes an \(\text {LR} \) query on a uniform message and the message \(0^n\). If the \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) challenge bit is 1 then it gets back a ciphertext \(C_1 = (\overline{\mathcal {E}} (k_{1},r) \Vert 0,r\oplus U)\) and if it is 0 then \(C_0 = (\overline{\mathcal {E}} (k_{1},r) \Vert 0,r)\). Next it queries \(\text {ReKeyGen} \) oracle on the first component of the returned ciphertext but with the trailing bit switched to 1. It asks for a rekey token for rotating from \(k_{1}\) back to \(k_{1}\). The value returned by this query is equal to \(\overline{\mathcal {E}} (k_{1},r') \Vert 0,r'\oplus k_{1} \oplus r\). By XOR’ing the second component with the second component returned from the \(\text {LR} \) query the adversary gets finally a ciphertext that is, in the left world, the encryption of \(k_{1}\) under itself and, in the right world, the encryption of a uniform point under \(k_{1}\). Adversary \({\mathcal {B}}\) runs a 1-circular adversary \({\mathcal {A}}\) on the final ciphertext and outputs whatever \({\mathcal {A}}\) outputs. \(\square \)
The above result uses 1-circular security for simplicity of presentation, but one can generalize the result to longer cycles by making more queries.
The result is relative, only showing that a proof of BLMR’s claim implies another reduction between circular security and IND-CPA security for the particular KEM/DEM scheme \(\textsf {Enc} \) above. It is possible that this reduction exists, however it seems unlikely. Existing counter-examples show IND-CPA schemes that are not circular-secure [KRW15]. While these counter-examples do not have the same form as the specific scheme under consideration, it may be that one can build a suitable counter-example with additional effort.
7 An Updatable AE Scheme with Re-encryption Indistinguishability
We first point out that one can avoid the issues raised in Sect. 6 by replacing the IND-CPA KEM with a proper AE scheme. This does not yet, however, address integrity of the full encryption scheme. To provide integrity overall, we can include a hash of the message in the ciphertext header. However, to prevent this from compromising confidentiality during re-keying, we further mask the hash by an extra PRF output.
This amended construction—which we refer to as ReCrypt—is detailed in Fig. 8. It uses an AE scheme \(\pi = (\mathcal {KG}, \mathcal {E}, \mathcal {D})\), a key-homomorphic PRF \(F: \mathcal {K}\times \mathcal {X}\rightarrow \mathcal {Y}\), and a hash function \(h: \{0,1\}^* \rightarrow \mathcal {Y}\).
In the remainder of this section we show that the new scheme meets our strongest security notions for updatable encryption. We then assess the viability of using this scheme in practice, discussing how to instantiate F for high performance and reporting on performance of the full scheme.

The ReCrypt scheme.
7.1 Security of ReCrypt
We state three security theorems for ReCrypt: UP-IND, UP-INT, and UP-REENC notions (proofs found in the full version). The proof of UP-INT relies on the collision resistance of the hash h, while the other two proofs do not. For simplicity, and because we will later instantiate the PRF F in the Random Oracle Model (ROM), we model h as a random oracle throughout our analysis. This modelling of h could be avoided using the approach of Rogaway [Rog06], since concrete collision-producing adversaries can be be extracted from our proofs. Note also that the almost key-homomorphic PRF construction in the standard model presented by BLMR would not achieve UP-REENC since the number of re-encryptions is leaked by the ciphertext, allowing an adversary to distinguish two re-encryptions.
Theorem 7
( \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) security of ReCrypt). Let \(\pi = (\mathcal {KG}, \mathcal {E}, \mathcal {D})\) be an AE scheme, \(F: \mathcal {K}\times \mathcal {X}\rightarrow \mathcal {Y}\) be a key-homomorphic PRF, and let \(\varPi \) be the ReCrypt scheme as depicted in Fig. 8.
Then for any adversary \({\mathcal {A}}\) against \(\varPi \), there exist adversaries \(\mathcal {B}\), \(\mathcal {C}\) such that

for all \(\kappa \ge 0, t \ge 1\).
Theorem 8
( \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) security of ReCrypt). Let \(\pi = (\mathcal {KG}, \mathcal {E}, \mathcal {D})\) be an AE scheme, \(F: \mathcal {K}\times \mathcal {X}\rightarrow \mathcal {Y}\) be a key-homomorphic PRF, h be a cryptographic hash function modelled as a random oracle with outputs in \(\mathcal {Y}\), and let \(\varPi \) be the ReCrypt scheme as depicted in Fig. 8.
Then for any adversary \({\mathcal {A}}\) against \(\varPi \), there exists an adversary \(\mathcal {B}\) such that

for all \(\kappa \ge 0, t \ge 1\), where the adversary makes \(q_h\) queries to h, and q oracle queries.
Theorem 9
( \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) security of ReCrypt). Let \(\pi = (\mathcal {KG}, \mathcal {E}, \mathcal {D})\) be an AE scheme, \(F: \mathcal {K}\times \mathcal {X}\rightarrow \mathcal {Y}\) be a key-homomorphic PRF, and let \(\varPi \) be the ReCrypt scheme as depicted in Fig. 8.
Then for any adversary \({\mathcal {A}}\) against \(\varPi \), there exist adversaries \(\mathcal {B}\), \(\mathcal {C}\) such that

for all \(\kappa \ge 0, t \ge 1\).
The proofs for \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \), UP-INT and UP-REENC follow a similar structure, proceeding in two phases. In the first phase, the AE security of \(\pi \) is used to show that the value of x is hidden from an adversary. In the second phase, the PRF security of F is used to show that outputs are indistinguishable to an adversary with no knowledge of x. Full proofs are found in the full version.
7.2 Instantiating the Key-Homomorphic PRF
We dedicate the remainder of this section to analysis of ReCrypt for use in practical scenarios. We delve into the implementation details of the key-homomorphic PRF in order to further explore some of the subtle security issues that arise when instantiating our scheme in practice.
While BLMR construct key-homomorphic PRFs in the standard model, a more efficient route is to use the classic ROM construction due originally to Naor, Pinkas, and Reingold [NPR99] in which \(F(k,x) = k\cdot H(x)\) where H is modelled as a random oracle \(H : \mathcal {X}\rightarrow \mathbb {G}\) and \(\mathbb {G}\) is a group (now written additively, since we shall shortly move to the elliptic curve setting) in which the decisional Diffie–Hellman (DDH) assumption holds.
Instantiation details. We will use (a subgroup of) \(\mathbb {G}= E(\mathbb {F}_p)\), an elliptic curve over a prime order finite field. However, recall that encryption is done block-wise as \(\overline{C}_l = m_l + F(x, l)\). Implicitly, it is assumed that messages m are already in the group \(\mathbb {G}\). To make a practical scheme for encrypting data represented as bitstrings, we additionally require an encoding function \(\sigma : \{0,1\}^n \rightarrow \mathbb {G}\).
Additionally, the existence of such a function proves useful in the construction of the PRF: we show how to instantiate the random oracle H using a regular cryptographic hash function \(h : \{0,1\}^* \rightarrow \{0,1\}^n\), modelled as a random oracle, together with the encoding function. We also use this definition of H for the instantiation of the random oracle used in the computation of the ciphertext header, which was needed to provide integrity. However, we add a unique prefix to inputs to either computation of H to provide separation.
For a suitable message encoding function, we of course require the function and its inverse to be efficiently computable. However, in addition we also require the inverse to be uniquely defined. Suppose \(\sigma ^{-1}\) is defined for all \(P \in \mathbb {G}\); then there is the possibility of creating a conflict with the integrity requirements. For example, suppose we have two points \(P, P'\) such that \(\sigma ^{-1}(P) = \sigma ^{-1}(P') = m\). Then an adversary can potentially exploit this collision in \(\sigma ^{-1}\) to construct a forged ciphertext. While this might not threaten the integrity of the plaintext, it would become problematic for ciphertext integrity.
One solution to this is to add a check to \(\sigma \) to verify that \(\sigma (\sigma ^{-1}(P)) = P\), and return \(\perp \) if not.
In the following theorem, we prove the security of the ReCrypt scheme when instantiated with a carefully chosen encoding function, and the Naor-Pinkas-Reingold PRF.
Theorem 10
Let \(\mathbb {G}= E(\mathbb {F}_p)\) be an elliptic curve of prime order in which the DDH assumption holds. For  let the encoding function \(\sigma : \{0,1\}^n \rightarrow \mathbb {G}\) be an injective mapping such that for any point P outside of the range, i.e. \(P \not \in \{\sigma (x) : x \in \{0,1\}^n\}\), then \(\sigma ^{-1}(P) = \perp \).
let the encoding function \(\sigma : \{0,1\}^n \rightarrow \mathbb {G}\) be an injective mapping such that for any point P outside of the range, i.e. \(P \not \in \{\sigma (x) : x \in \{0,1\}^n\}\), then \(\sigma ^{-1}(P) = \perp \).
Let \(H : \{0,1\}^n \rightarrow \mathbb {G}\) be defined as \(H(x) = \sigma (h(x))\) for a cryptographic hash function h modelled as a random oracle.
Then \(F(k, x) = k \cdot H(x)\) is a key-homomorphic PRF.
By rejecting encoded messages outside of the range of \(\sigma \), we effectively restrict \(\sigma \) to be a bijection from \(\{0,1\}^n\) to a subset of \(\mathbb {G}\). Given this, it is easy to see instantiating ReCrypt with this message encoding and key-homomorphic PRF results in a secure updatable AE scheme as proven above.
We identified two candidates for the message encoding function. The first uses rejection sampling, in which a bitstring is first treated as an element of \(\mathbb {F}_p\), with some redundancy, and subsequently mapped to the elliptic curve. If a matching point cannot be found on the curve, the value is incremented (using the redundancy) and another attempt is made. Repeating this process results in a probabilistic method.
Corollary 1
Define the encoding function \(\sigma : x \mapsto E(\mathbb {F}_p)\) mapping bitstrings of length n to group elements by first equating the bitstring as an element \(x \in \mathbb {F}_p\). Let \(\bar{x}\) be the minimum value of the set \(\{ x + i\cdot 2^n \; : \; 0 \le i < \left\lfloor \frac{p}{2^n}\right\rfloor \}\) such that \((\bar{x}, y) \in E(\mathbb {F}_p)\) for some y. Then define \(\sigma (x)\) to be the point \((\bar{x}, \bar{y})\) where \(\bar{y} = \min \{y, p-y\}\).
The inverse mapping \(\sigma ^{-1}(P)\) is computed by taking the x-coordinate and reducing mod \(2^n\). I.e. set \(x' = x(P) \mod 2^n\) and verify \(P \ne \sigma (x')\), otherwise return \(\perp \).
Then \(\sigma \) satisfies the requirements of Theorem 10.
See the full version Theorem 10 and Corollary 1.
As an alternative to rejection sampling, an injective mapping can be used directly, again first treating the bitstring as an element of \(\mathbb {F}_p\). Some examples include the SWU algorithm [SvdW06], Icart’s function [Ica09], and the Elligator encoding [BHKL13].
Corollary 2
For a compatible elliptic curve \(E(\mathbb {F}_p)\), the Elligator function as defined in [BHKL13] satisfies the requirement of Theorem 10 for all \(m \in \{0,1\}^{\left\lfloor \log (p-1)\right\rfloor - 1}\).
Proof
The Elligator function maps injectively from \(\{ 1, \ldots , \frac{p-1}{2} \}\) to \(E(\mathbb {F}_p)\). For the inverse map, if the returned value is greater than \(\frac{p-1}{2}\), we return \(\perp \). \(\square \)
7.3 Implementation and Performance
We now provide a concrete instantiation of the ReCrypt scheme using the method described in Sect. 7.2 and report on the performance of our prototype implementation. Our goal is assess the performance gap between in-use schemes that do not meet \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) security, and ReCrypt, which does.
Implementation. We built our reference implementation using the Rust [MKI14] programming language. This implementation uses Relic [AG], a cryptographic library written in C, and the GNU multi-precision arithmetic library (GMP). Our implementation is single-threaded and we measured performance on an Intel CPU (Haswell), running at 3.8 GHz in turbo mode.
We use secp256k1 [Cer00] for the curve and SHA256 as the hash function h. The plaintext block length is 31 bytes. We use AES128-GCM for the AE scheme \(\pi \).
The Relic toolkit provided a number of different curve options, as well as access to the low level elliptic curve operations which was essential in our early prototyping and testing. However, Relic does not at the time of writing support curves in Montgomery form, and therefore has an inefficient implementation of scalar multiplication on Curve25519. Therefore, we choose secp256k1 because it was the most performant among all curve implementations at our disposal with (approximately) 128 bits of security. We project that Curve25519 would offer comparable efficiency, whereas a hand-tuned, optimised variant of a specific curve would result in a significant speedup.
We use a 31-byte block size with the random sampling encoding algorithm, resulting in a probability of \(1 {-} 2^{-256}\) to find a valid encoding for each block.
We also experimented with the injective encodings such as the Elligator encoding [BHKL13]. The mapping did not appear to improve performance, and moreover is incompatible with secp256k1. Additionally, we do not require ciphertexts to be indistinguishable from random, one of the key benefits offered by the Elligator encoding.
When a curve point is serialized, only the x coordinate and the sign of the y coordinate (1-bit) needs to be recorded (using point compression). Since the x coordinate requires strictly less than the full 32 bytes, we can serialize points as 32 byte values. Each 32 byte serialized value represents 31 bytes of plaintext giving a ciphertext expansion of 3%. Upon deserialization, the y coordinate must be recomputed. This requires computing a square root, taking approximately 20 µs. Of course this cost can be avoided by instead serializing both x and y coordinates. This creates a 64 byte ciphertext for each 31 bytes of plaintext which is an expansion of 106%. We consider that to be unacceptable.

Processing times for ReCrypt operations measured on a 3.8 GHz CPU. 1 block represents any plaintext \(\le \)31 bytes. Number of iterations: 1000 (for 1 block, 1 KB), 100 (for 1 MB) and 1 (for 1 GB). Cycles per byte given for 1MB ciphertexts.
Microbenchmarks. Figure 9 shows wall clock times for ReCrypt operations over various plaintext sizes. As might be expected given the nature of the cryptographic operations involved, performance is far from competitive with conventional AE schemes. For comparison, AES-GCM on the same hardware platform encrypts 1 block, 1 KB, 1 MB and 1 GB of plaintext in 15 µs, 24 µs, 9 ms, and 11 s, respectively. KSS has performance determined by that of AES-GCM, while the performance of the ReCrypt scheme is largely determined by the scalar multiplications required to evaluate the PRF. Across all block sizes there is a 1000x performance cost to achieve our strongest notion of security.
Discussion. Given this large performance difference, ReCrypt is best suited to very small or very valuable plaintexts (ideally, both). Compact and high-value plaintexts such as payment card information, personally identifiable information, and sensitive financial information are likely targets for ReCrypt. If the plaintext corpus is moderately or very large, cost and performance may prohibit practitioners from using ReCrypt over more performant schemes like KSS that give strictly weaker security.
8 Conclusion and Open Problems
We have given a systematic study of updatable AE, providing a hierarchy of security notions meeting different real-world security requirements and schemes that satisfy them efficiently. Along the way, we showed the limitations of currently deployed approach, as represented by AE-hybrid, improved it at low cost to obtain the \(\mathrm{{KSS}}\) scheme meeting our \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) notions, identified a flaw in the BLMR scheme, repaired it, and showed how to instantiate the repaired scheme in the ROM. Through this, we arrived at \({\mathrm{{ReCrypt}}}\), a scheme that is secure in our strongest security models (\(\mathrm{{UP}}\text {-}\mathrm{{IND}} \), \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \)). We implemented \({\mathrm{{ReCrypt}}}\) and presented basic speed benchmarks for our prototype. The scheme is slow compared to the hybrid approaches but offers true key rotation.
Our work puts updatable AE on a firm theoretical foundation and brings schemes with improved security closer to industrial application. While there is a rich array of different security models for practitioners to chose from, it is clear that achieving strong security (currently) comes at a substantial price. Meanwhile weaker but still useful security notions can be achieved at almost zero cost over conventional AE. It is an important challenge to find constructions which lower the cost compared to ReCrypt without reducing security. But it seems that fundamentally new ideas will be needed here, since what are essentially public key operations are intrinsic to our construction.
From a more theoretical perspective, it would also be of interest to study the exact relations between our security notions, in particular whether \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) is strong enough to imply \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{INT}} \). There is also the question of whether a scheme that is \(\mathrm{{UP}}\text {-}\mathrm{{REENC}} \) is necessarily ciphertext-dependent. Finally, we reiterate the possibility of formulating updatable AE in the nonce-based setting.
Notes
- 1.
BLMR called this ciphertext independence, but we reserve that terminology for schemes that do not require ciphertexts during token generation as per Sect. 2.
- 2.
Such a scheme can be constructed by adding a redundant ciphertext bit to an existing \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \)-secure scheme, with the redundant bit being randomly generated during encryption and preserved across re-encryptions.
- 3.
Notice that this scheme is not tidy in the sense of [NRS14]. While that doesn’t affect the implications of our analysis—BLMR make no assumptions about tidiness—finding a tidy counter-example is an interesting open question.
References
Acar, T., Belenkiy, M., Bellare, M., Cash, D.: Cryptographic agility and its relation to circular encryption. In: Gilbert, H. (ed.) EUROCRYPT 2010. LNCS, vol. 6110, pp. 403–422. Springer, Heidelberg (2010). doi:10.1007/978-3-642-13190-5_21
Andreeva, E., Bogdanov, A., Luykx, A., Mennink, B., Mouha, N., Yasuda, K.: How to securely release unverified plaintext in authenticated encryption. In: Sarkar, P., Iwata, T. (eds.) ASIACRYPT 2014. LNCS, vol. 8873, pp. 105–125. Springer, Heidelberg (2014). doi:10.1007/978-3-662-45611-8_6
Aranha, D.F., Gouvêa, C.P.L.: RELIC is an efficient library for cryptography. https://github.com/relic-toolkit/relic
AWS: Protecting data using client-side encryption. http://docs.aws.amazon.com/AmazonS3/latest/dev/UsingClientSideEncryption.html
Boldyreva, A., Degabriele, J.P., Paterson, K.G., Stam, M.: On symmetric encryption with distinguishable decryption failures. In: Moriai, S. (ed.) FSE 2013. LNCS, vol. 8424, pp. 367–390. Springer, Heidelberg (2014). doi:10.1007/978-3-662-43933-3_19
Bernstein, D.J., Hamburg, M., Krasnova, A., Lange, T.: Elligator: elliptic-curve points indistinguishable from uniform random strings. In: Sadeghi, A.-R., Gligor, V.D., Yung, M. (eds.) ACM CCS 2013, pp. 967–980. ACM Press, November 2013
Bellare, M., Kohno, T.: A theoretical treatment of related-key attacks: RKA-PRPs, RKA-PRFs, and applications. In: Biham, E. (ed.) EUROCRYPT 2003. LNCS, vol. 2656, pp. 491–506. Springer, Heidelberg (2003). doi:10.1007/3-540-39200-9_31
Boneh, D., Lewi, K., Montgomery, H., Raghunathan, A.: Key homomorphic PRFs and their applications. In: Canetti, R., Garay, J.A. (eds.) CRYPTO 2013. LNCS, vol. 8042, pp. 410–428. Springer, Heidelberg (2013). doi:10.1007/978-3-642-40041-4_23
Boneh, D., Lewi, K., Montgomery, H., Raghunathan, A.: Key homomorphic PRFs and their applications. Cryptology ePrint Archive, Report 2015/220 (2015). http://eprint.iacr.org/2015/220
Bellare, M., Namprempre, C.: Authenticated encryption: relations among notions and analysis of the generic composition paradigm. In: Okamoto, T. (ed.) ASIACRYPT 2000. LNCS, vol. 1976, pp. 531–545. Springer, Heidelberg (2000). doi:10.1007/3-540-44448-3_41
Black, J., Rogaway, P., Shrimpton, T.: Encryption-scheme security in the presence of key-dependent messages. In: Nyberg, K., Heys, H. (eds.) SAC 2002. LNCS, vol. 2595, pp. 62–75. Springer, Heidelberg (2003). doi:10.1007/3-540-36492-7_6
SEC Certicom: Sec 2: Recommended elliptic curve domain parameters. In: Proceeding of Standards for Efficient Cryptography, Version 1 (2000)
Cash, D., Green, M., Hohenberger, S.: New definitions and separations for circular security. In: Fischlin, M., Buchmann, J., Manulis, M. (eds.) PKC 2012. LNCS, vol. 7293, pp. 540–557. Springer, Heidelberg (2012). doi:10.1007/978-3-642-30057-8_32
Canetti, R., Hohenberger, S.: Chosen-ciphertext secure proxy re-encryption. In: Ning, P., De Capitani di Vimercati, S., Syverson, P.F. (eds.) ACM CCS 2007, pp. 185–194. ACM Press, October 2007
Cool, D.L., Keromytis, A.D.: Conversion and proxy functions for symmetric key ciphers. In: International Conference on Information Technology: Coding and Computing, ITCC 2005, vol. 1, pp. 662–667. IEEE (2005)
Camenisch, J., Lysyanskaya, A.: An efficient system for non-transferable anonymous credentials with optional anonymity revocation. In: Pfitzmann, B. (ed.) EUROCRYPT 2001. LNCS, vol. 2045, pp. 93–118. Springer, Heidelberg (2001). doi:10.1007/3-540-44987-6_7
Google: Managing data encryption. https://cloud.google.com/storage/docs/encryption
Icart, T.: How to hash into elliptic curves. In: Halevi, S. (ed.) CRYPTO 2009. LNCS, vol. 5677, pp. 303–316. Springer, Heidelberg (2009). doi:10.1007/978-3-642-03356-8_18
Ivan, A., Dodis, Y.: Proxy cryptography revisited. In: NDSS 2003. The Internet Society, February 2003
Koppula, V., Ramchen, K., Waters, B.: Separations in circular security for arbitrary length key cycles. In: Dodis, Y., Nielsen, J.B. (eds.) TCC 2015. LNCS, vol. 9015, pp. 378–400. Springer, Heidelberg (2015). doi:10.1007/978-3-662-46497-7_15
Matsakis, N.D., Klock II, F.S.: The rust language. ACM SIGAda Ada Lett. 34(3), 103–104 (2014)
Naor, M., Pinkas, B., Reingold, O.: Distributed pseudo-random functions and KDCs. In: Stern, J. (ed.) EUROCRYPT 1999. LNCS, vol. 1592, pp. 327–346. Springer, Heidelberg (1999). doi:10.1007/3-540-48910-X_23
Namprempre, C., Rogaway, P., Shrimpton, T.: Reconsidering generic composition. In: Nguyen, P.Q., Oswald, E. (eds.) EUROCRYPT 2014. LNCS, vol. 8441, pp. 257–274. Springer, Heidelberg (2014). doi:10.1007/978-3-642-55220-5_15
PCI Security Standards Council: Requirements and security assessment procedures. In: PCI DSS v3.2 (2016)
Paterson, K.G., Ristenpart, T., Shrimpton, T.: Tag size Does matter: attacks and proofs for the TLS record protocol. In: Lee, D.H., Wang, X. (eds.) ASIACRYPT 2011. LNCS, vol. 7073, pp. 372–389. Springer, Heidelberg (2011). doi:10.1007/978-3-642-25385-0_20
Rogaway, P.: Formalizing human ignorance. In: Nguyen, P.Q. (ed.) VIETCRYPT 2006. LNCS, vol. 4341, pp. 211–228. Springer, Heidelberg (2006). doi:10.1007/11958239_14
Rogaway, P., Shrimpton, T.: Deterministic authenticated-encryption: a provable-security treatment of the key-wrap problem. Cryptology ePrint Archive, Report 2006/221 (2006). http://eprint.iacr.org/2006/221
Ristenpart, T., Shacham, H., Shrimpton, T.: Careful with composition: limitations of the indifferentiability framework. In: Paterson, K.G. (ed.) EUROCRYPT 2011. LNCS, vol. 6632, pp. 487–506. Springer, Heidelberg (2011). doi:10.1007/978-3-642-20465-4_27
Edixhoven, B.: On the computation of the coefficients of a modular form. In: Hess, F., Pauli, S., Pohst, M. (eds.) ANTS 2006. LNCS, vol. 4076, pp. 30–39. Springer, Heidelberg (2006). doi:10.1007/11792086_3
Acknowledgements
We thank the anonymous Crypto reviewers for their feedback and discussion relating to a bug in our initial KSS construction, and for their additional comments and suggestions. This work was supported in part by NSF grant CNS-1330308, EPSRC grants EP/K035584/1 and EP/M013472/1, by a research programme funded by Huawei Technologies and delivered through the Institute for Cyber Security Innovation at Royal Holloway, University of London, and a gift from Microsoft.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
A Bidirectional Updatable AE
A Bidirectional Updatable AE
1.1 A.1 XOR-KEM: A Bidirectional Updatable AE Scheme
The AE-hybrid and KSS schemes are unidirectional and ciphertext-dependent. This means that in practice the client must fetch from storage ciphertext headers in order to compute the rekey tokens needed to update individual ciphertexts. It could be simpler to utilize a ciphertext-independent scheme that has rekey tokens that work for any ciphertext encrypted with a particular key. This would make the re-encryption process “non-interactive”, requiring that the key holder only push a single rekey token to the place where ciphertexts are stored. Given the obvious performance benefits that such a scheme would have, we also provide such a scheme, called XOR-KEM. This scheme is exceptionally fast, and is built from a (non-updatable) AE scheme that is assumed to be secure against a restricted form of related-key attack (RKA). This latter notion adapts the Bellare-Kohno RKA-security notions for block ciphers [BK03] to the setting of AE schemes. To the best of our knowledge, this definition is novel, and RKA secure AE may itself be of independent interest as a primitive. However, the XOR-KEM scheme cannot meet our integrity notions against an attacker in possession of compromised keys. (And because of its bidirectionality, XOR-KEM also provides the counter-example that we used to separate \(\mathrm{{UP}}\text {-}\mathrm{{IND}}\text {-}\mathrm{{BI}} \) and \(\mathrm{{UP}}\text {-}\mathrm{{IND}} \) security in Sect. 3.1.)
Let (\(\mathcal {K}\), \(\mathcal {E}\), \(\mathcal {D}\)) be an AE scheme. Then we define the ciphertext-independent scheme, XOR-KEM, as follows:
-
\(\textsf {KeyGen} ()\): \(\text {return} ~k\leftarrow \mathcal {K}\)
-
\(\textsf {Enc} (k_{},m)\): \(x \leftarrow \mathcal {K};\) \(C \leftarrow (x \oplus k_{}, \mathcal {E}(x,M));\) \(\text {return} ~C\)
-
\(\textsf {ReKeyGen} (k_{1}, k_{2})\):

-
 :
:  \(\text {return} ~C'\)
\(\text {return} ~C'\)
-
\(\textsf {Dec} (k_{}, C = (C_0, C_1))\): \(\text {return} ~\mathcal {D}(C_0 \oplus k_{},C_1)\)

 :
: 
The XOR-KEM scheme has a similar format to the AE-hybrid scheme above. However, instead of protecting the DEM key x by encrypting it, we instead XOR it with the secret key \(k_{}\). The resulting scheme becomes a bidirectional, ciphertext-independent scheme, and one that has extremely high performance and deployability.
Note that although the value \(x \oplus k_{}\) fulfils a similar purpose as the ciphertext header in AE-hybrid, since this value is not needed in re-keying, it resides in the ciphertext body.
We provide proofs in the full version that this scheme achieves UP-IND-BI, and UP-INT-BI. However, the latter only holds when the adversary does not have access to any corrupted keys, and relies on the AE scheme being secure against a class of related-key attacks.
Rights and permissions
Copyright information
© 2017 International Association for Cryptologic Research
About this paper
Cite this paper
Everspaugh, A., Paterson, K., Ristenpart, T., Scott, S. (2017). Key Rotation for Authenticated Encryption. In: Katz, J., Shacham, H. (eds) Advances in Cryptology – CRYPTO 2017. CRYPTO 2017. Lecture Notes in Computer Science(), vol 10403. Springer, Cham. https://doi.org/10.1007/978-3-319-63697-9_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-63697-9_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-63696-2
Online ISBN: 978-3-319-63697-9
eBook Packages: Computer ScienceComputer Science (R0)
